Cómo rescaté un juego de USENET de 1987, rastreé a sus creadores a través del tiempo y lo llevé a la era moderna
Autor: Juan Méndez (vejeta) | Septiembre 2025
PRÓLOGO: El Eco de un Mundo Perdido
«I heard news of the request to release the code. I grant permission to release the code under GPL.»
— Adam Bryant, 23 de febrero de 2011
«I enjoyed the article and liked seeing the map images in particular. It definitely brought back very fond memories! If only working a job to pay the bills hadn’t gotten in the way…»
— Adam Bryant, septiembre de 2025
Catorce años separan estos dos mensajes. El primero rescató un proyecto estancado; el segundo reveló la profundidad emocional de una era digital que ya no existe. Esta es la historia de cómo una obsesión de dos décadas devolvió la voz a los pioneros del software y tendió un puente entre dos Internet irreconciliables.
CAPÍTULO 1: La Cápsula del Tiempo Digital (1987)
Imagen: Captura completa del posting original de «conquest» mostrando el código shar.
26 de octubre de 1987. Mientras la mayoría del mundo ni siquiera imaginaba Internet, en los servidores de USENET un usuario llamado ihnp4!mhuxd!smile (Edward Barlow) publicaba en comp.sources.games:
v02i058: conquest – middle earth multi-player game, Part01/05
Este mensaje era más que un anuncio; era un artefacto de una filosofía que definiría una era.
La Logística del shar: Cuando el Software Viajaba en Fragmentos
Descargar Conquer en 1987 no era un clic. Era un rito de iniciación técnica:
bash
#! /bin/sh
# This is a shell archive. Remove anything before this line, then unpack
# it by saving it into a file and typing «sh file».
Cada una de las 5 partes era un script que contenía el código codificado como texto. El proceso requería:
- Descargar manualmente cada parte desde USENET
- Ejecutar sh parte01 para reconstruir los archivos
- Repetir para las partes 2-5
- Compilar manualmente con cc -o conquer *.c -lcurses
Si fallaba la parte 3, el proceso se detenía. No había resume download. Se esperaba días o semanas hasta que reapareciera en el feed.
El Acto de Fe Colectivo
Publicar en comp.sources.games era enviar tu trabajo al escrutinio de miles de los mejores ingenieros del mundo. No había tiendas curadas ni revisiones previas. La comunidad era el control de calidad.
Ed Barlow incluía esta nota en el README:
«What you have here is a copyrighted beta test version of CONQUEST.»
No existían las «betas cerradas». Se confiaba en que usuarios anónimos en universidades de todo el mundo probarían, reportarían errores y mejorarían el código. Era el open source antes de que el término existiera.
CAPÍTULO 2: Días Universitarios – El Descubrimiento (1990s)


Fotografía de los laboratorios Unix de la Universidad de Sevilla en los años 90.
A mediados de los 90, siendo estudiante en Sevilla, pasé incontables horas en los laboratorios Unix explorando un mundo digital emergente: terminales verdes, USENET, links, news, msgs – y, por supuesto, Conquer.
El juego era revolucionario. Como líder de una nación, controlabas tu reino élfico, imperio orco o ejércitos humanos a través de un mapa renderizado en caracteres ASCII. La profundidad era asombrosa:
- Gestión económica detallada por sectores
- Sistemas diplomáticos complejos entre razas
- Magia y hechizos con efectos en el mundo
- Exploración de territorios desconocidos
El Ritual Social del Juego
No era un juego solitario. El ritual era profundamente social:
- Conectar por SSH a una máquina Unix compartida
- Hacer movimientos durante el día entre clases
- Esperar el conqrun nocturno que procesaba los turnos
- Recibir emails con los resultados cada mañana
Organizamos partidas que duraban semanas, con turnos diarios o semanales. La lentitud era una característica, no un defecto. Permitía la estrategia profunda y creaba comunidad alrededor del texto.
No he encontrado fotos de la época de la sala, pero he encontrado su descripción en las antiguas páginas de la facultad:
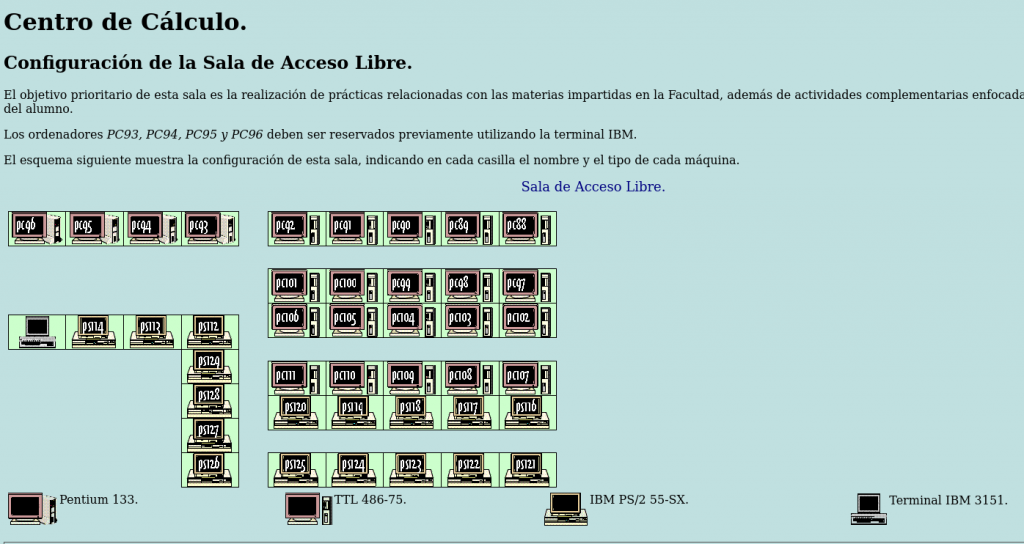
CAPÍTULO 3: La Búsqueda Comienza – Detective Digital (2006)
Imagen: Captura completa del hilo en debian-legal mostrando la consulta inicial.
Para 2006, esta pieza de historia computacional estaba atrapada en un limbo legal. Comencé lo que pensé que sería un proyecto simple: obtener permiso para relicenciar el código bajo GPL y empaquetarlo para distribuciones Linux modernas.
Encontrar a los autores originales fue arqueología digital. Los emails de los 80 llevaban años muertos. Examiné directorios universitarios antiguos, seguí migas de pan digitales y eventualmente contacté a Ed Barlow.
La Filosofía del «Hazlo y Ve Qué Pasa»
Nuestra conversación por mensajería en 2006 reveló la mentalidad de la era:
(18:08:58) vejeta: Sorry if I catch you busy. While trying to investigate if I could relicense old conquer as free software I discovered it was complex.
(18:14:00) Ed Barlow: i personally would say that you should do it and nobody will know the difference
(18:18:52) vejeta: Indeed, I feel like a detective 🙂
(18:21:23) Ed Barlow: v4 was both of ours… i wrote v4 he wrote v5…
Cuando pregunté sobre arreglos comerciales previos, su respuesta fue reveladora:
«i dont know… i dont have adams mail address at all… dunno if they did anythign with the license tho»
Esta actitud encapsulaba la era pre-comercial de Internet: construir por pasión, compartir por defecto.
Pero Adam Bryant había desaparecido en el éter digital. Documenté todo en las listas de Debian Legal y creé la tarea GNU Savannah #5945. El proyecto se estancó.
CAPÍTULO 4: La Larga Espera y el Avance Inesperado (2006-2011)
Imagen: Captura del email de Adam Bryant de 2011 llegando espontáneamente.
Pasaron años. Entonces, el 23 de febrero de 2011, ocurrió la magia. Mi teléfono vibró con un envío de formulario de contacto:
«I heard news of the request to release the code. I grant permission to release the code under GPL.» – Adam Bryant
Había encontrado uno de mis artículos en línea y contactó espontáneamente. Después de cinco años de búsqueda, la barrera principal había desaparecido.
La Comunidad como Memoria Colectiva
Mientras tanto, conversaciones informales mantuvieron viva la llama. En 2011, mientras explicaba el proyecto a un amigo, su entusiasmo fue contagioso:
kike: killo me has dejao to intringao con el conquer no le puedes hacer eso a un puto ludópata como yo XDDD
vejeta: …Esto fue la epoca pre-internet. Y nos entreteniamos con otras cosas: saltarnos las protecciones, juegos como el conquer, dominion, el arte ascii :). El irc acabó con todo eso.
kike: si necesitas mano de obra barata para algo del conquer, cueneta conmigo…
Estos diálogos muestran que el proyecto nunca fue un fin en sí mismo, sino un vehículo para revivir una forma de entender la tecnología.
CAPÍTULO 5: La Trama se Complica – Versión 5 Emerge (2025)
Imagen: Comparación lado a lado de las interfaces de Conquer v4 y v5.
Justo cuando la historia parecía completa, Stephen Smoogen me contactó en 2025 sobre mis esfuerzos de relicenciamiento de 2006. Estaba particularmente interesado en Conquer Versión 5 – la reescritura completa de Adam Bryant con características avanzadas:
- Conversión automática de datos entre versiones
- Estabilidad mejorada y herramientas administrativas
- Sistemas de eventos sofisticados
- Interfaz de administración expandida
Pero V5 tenía una historia legal diferente, incluyendo arreglos comerciales de los 90. ¿Aceptaría Adam licenciar GPL esta versión también?
Su respuesta: «I have no issues with applying a new GPL license to Version 5 as well.»
El Arco de 14 Años
El viaje de Adam entre sus dos mensajes cuenta una historia universal:
2011: «I grant permission to release the code under GPL.»
2025: «If only working a job to pay the bills hadn’t gotten in the way…»
Este arco de 14 años revela la tensión eterna entre pasión y responsabilidad que todo creador enfrenta.
CAPÍTULO 6: Las Piezas Perdidas – Magia PostScript y una Pérdida Trágica
Imagen: Ejemplo de salida PostScript de las utilidades de MaF.
La red de contribuyentes se expandió. Descubrí a MaF (Martin Forssen), quien creó utilidades PostScript para generar mapas imprimibles del juego – crucial en la era pre-GUI cuando los jugadores necesitaban copias físicas para estrategizar.
Rastrear a MaF en 2025 me llevó a su nueva dirección de correo electrónico. Su respuesta fue inmediata y generosa: «Oh, that was a long time ago. But yes, that was me. And I have no problem with relicensing it to GPL.»
Richard Caley: No Solo un Pie de Página Legal

Captura de la página principal de Richard Caley preservada mostrando el anuncio.
Pero no todas las búsquedas terminan con una respuesta. Algunas terminan con silencio.
Mi investigación sobre Richard Caley siguió las mismas migas de pan digitales. Lo tracé hasta la Universidad de Edimburgo, donde trabajó en síntesis de voz. Encontré sus contribuciones técnicas a FreeBSD. Pero el rastro se enfrió alrededor de 2005.
Entonces lo encontré – no en un archivo de USENET, sino en la portada de su propio sitio web, preservado exactamente como lo dejó:
«Richard Caley suffered a fatal heart attack on the 22nd of April, 2005. He was only 41, but had been an undiagnosed diabetic, probably for some considerable time. His web pages remain as he left them.»
Leer esas palabras se sintió diferente a encontrar un registro histórico. Esto no era investigación archivística – era entrar a la casa de alguien años después de que se hubiera ido y encontrar una nota en la mesa.
La página continuaba:
«Over and above his tremendous ability with computers and programming, Richard had a keen mind and knowledge of an extraordinary range of topics, both of which he used in frequent contributions to on-line discussions. Despite his unique approach to speling, his prolific contributions to various news group debates informed and amused many over the years.»
Los «Caleyisms» – El Hombre Detrás del Código
Captura de la página «Caleyisms» mostrando sus respuestas ingeniosas.

Y entonces descubrí sus «Caleyisms» – una colección curada de sus respuestas más brillantes en USENET que revelaban no solo a un programador, sino a una persona:
What’s a shell suit?
«Oil company executive.»
How do you prepare for a pyroclastic flow hitting Edinburgh?
«Hang 1000 battered Mars bars on strings and stand back?»
On his book addiction:
«I never got the hang of libraries, they keep wanting the things back and get upset when they need a crowbar to force it out of my hands.»
Su humor era seco, inteligente y únicamente británico. En discusiones técnicas, podía ser brutalmente preciso:
«Lack of proper punctuation, spacing, line breaks, capitalisation etc. is like bad handwriting, it doesn’t make it impossible to read what was written, just harder. But you probably write in green crayon anyway.»*
El Oficina Digital Preservada
Explorar su sitio web preservado se sintió como caminar por su oficina digital. La estructura de directorios revelaba sus pasiones: how-tos de FreeBSD, experimentos con POVRAY, imágenes de fondo, proyectos técnicos. Su humor auto-despreciativo brillaba en su sección «About»:
«Thankfully I don’t have a photograph to inflict on you. Just use the picture of Iman Bowie to the left and then imagine someone who looks exactly the opposite in every possible way. This probably explains why she is married to David Bowie and I’m not.»*
Aquí había una persona completa – director técnico en Interactive Information Ltd, investigador de síntesis de voz, entusiasta de FreeBSD, fan de Kate Bush, y un ingenio que alegró incontables discusiones en línea.
La realidad legal era dura: las contribuciones de Richard a Conquer no podían ser relicenciadas. La universidad no pudo ayudar a contactar herederos debido a leyes de privacidad.
Imagen: El arte ASCII RIP de la página de Richard.
Sus amigos habían preservado su memoria con un simple tributo ASCII al final de su página:
text
^_^
(O O)
\_/@@\
\\~~/
~~
- RJC RIP
En la documentación del proyecto Conquer, Richard Caley no es recordado como un «caso problemático» o «código no liberable». Es honrado como la persona vibrante que fue – la mente brillante detrás de los «Caleyisms», el investigador que contribuyó a la síntesis de voz, el defensor de FreeBSD, y el participante ingenioso en comunidades en línea tempranas cuyas palabras continúan divirtiendo e informando, décadas después de que las escribiera.
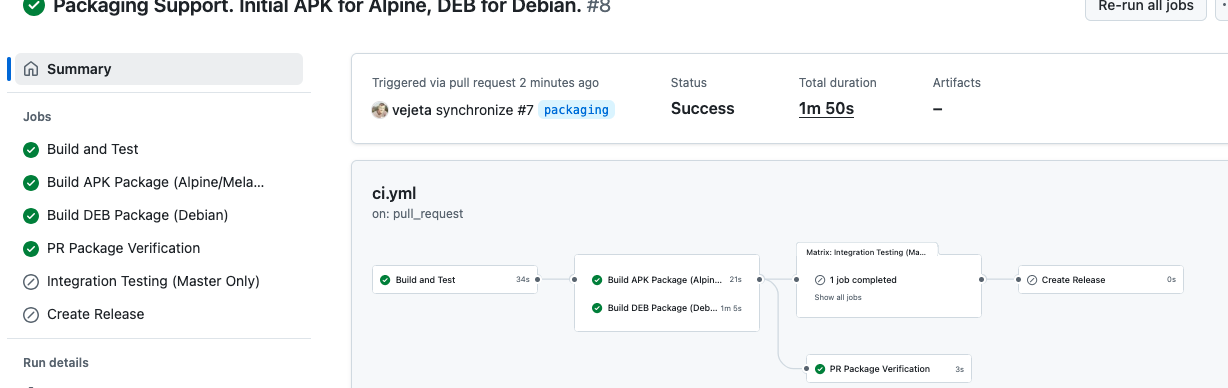
CAPÍTULO 7: Renacimiento Técnico – Del USENET al CI/CD
Imagen: Comparación lado a lado mostrando el archivo shar de 1987 y la configuración de GitHub Actions de 2025.
La transformación técnica ha sido notable. Modernizar código de 1987 presenta desafíos únicos que requieren tanto respeto por el original como adopción de tecnologías modernas.
Arqueología del Makefile
# Original 1987 - Dependencias hardcodeadas
conquer: conquer.c utils.c
cc -o conquer conquer.c utils.c -lcurses -ltermcap
# Moderno 2025 - Autotools y detección automática
AC_INIT([conquer], [4.6])
AC_PROG_CC
AC_CHECK_LIB([ncurses], [initscr])
Tuve que reemplazar assumptions de sistemas antiguos con detección automática de bibliotecas. Los Makefiles originales asumían versiones específicas de curses y ubicaciones de bibliotecas que ya no existen.
La Magia de ttyd – Terminales en la Web
# Dockerfile fragment - Puente tecnológico perfecto
FROM alpine:latest
RUN apk add ttyd ncurses
COPY conquer /usr/local/bin/
CMD ["ttyd", "-p", "7681", "conquer"]
Esta configuración permite que la interfaz de curses original se renderice en navegadores modernos sin modificar una línea del código de 1987. Es un puente tecnológico que respeta el original mientras permite acceso moderno.
Melange y el Empaquetado Reproducible
# conquer.yaml - Construcción reproducible APK
package:
name: conquer
version: 4.6
description: "1987 USENET multiplayer strategy game"
environment:
contents:
packages:
- ncurses-dev
- gcc
El mismo juego que viajaba en 5 partes de USENET ahora genera paquetes binarios con hashes criptográficos y procedencia verificable. La ironía: descubrí Melange cuando un amigo empezó a trabajar para la empresa que lo creó.
Flujo CI/CD Completo
yaml
# GitHub Actions workflow
- name: Build APK package
run: melange build conquer.yaml
- name: Build Debian package
run: dpkg-buildpackage -b
- name: Docker build
run: docker build -t conquer:latest .
Logros Técnicos Clave:
- Relicenciamiento GPLv3 para ambas v4 y v5
- Sistema de construcción moderno con autotools
- Base de código C actualizada para soportar ANSI C99 moderno
- Empaquetado Debian integración
- Empaquetado APK con Melange para Alpine Linux
- Contenedores Docker con emulación de terminal via WebSockets
CAPÍTULO 8: Contexto Histórico – Conquer en el Ecosistema de Juegos Unix
Imagen: Fragmento de la lista «versions of empire» de 1989 mostrando a Conquer entre otros juegos.
Conquer no existía en el vacío. La lista «versions of empire» de 1989 revela un ecosistema floreciente de juegos de estrategia multiplayer:
- Empire (PSL, UCB, UCSD): Diferentes variantes mantenidas por universidades
- Galactic Bloodshed: Enfocado en exploración y terraformación
- xconq: Uno de los primeros en ofrecer interfaz X Window
- Buck Empire: Mejoras y debugging de una versión de PSL Empire
¿Por qué Conquer Sobrevivió Cuando Otros Desaparecieron?
- Arquitectura Modular: Fácil de extender con nuevas razas y hechizos
- Documentación Completa: Incluía guías de administración y formato de datos
- Comunidad Activa: Adam Bryant mantuvo parches durante años
- Portabilidad: Escrito en C estándar, sin dependencias exóticas
Mientras juegos comerciales de la misma época desaparecieron con sus plataformas, Conquer sobrevivió porque era texto plano y código abierto antes de que el término existiera.
La lista de 1989 presentaba a Conquer así:
«A multiplayer fantasy wargame written from scratch by Ed Barlow… Not really empire, but close enough to be easily understood by those used to empire. Currently supported by co-author Adam Bryant.»
Esto revela una cultura donde los «competidores» se listaban unos a otros en un espíritu de comunidad. El valor no estaba en la propiedad intelectual, sino en la contribución a un ecosistema común.
CAPÍTULO 9: El Elemento Humano – Por Qué Esta Odisea de 20 Años Importa
Imagen: Collage mostrando el código original de Ed Barlow, el email de Adam Bryant de 2011, y la conversación del equipo de 2025.
Esto no es solo sobre preservar juegos. Es sobre preservar la historia misma de la computación.
Los Pioneros del Software
Ed Barlow y Adam Bryant construyeron experiencias multiplayer sofisticadas cuando la mayoría de la gente nunca había oído hablar de Internet. Distribuyeron software a través de USENET porque eso era lo que se hacía – compartías cosas geniales con la comunidad.
Martin Forssen y sus utilidades PostScript representan el ingenio de los desarrolladores tempranos que resolvían problemas con las herramientas disponibles. ¿Querías visualizar el estado del juego? ¡Escribías un generador PostScript!
Comunidad y Continuidad
El esfuerzo de relicenciamiento de 20 años demuestra algo crucial sobre el open source: no es solo sobre código, es sobre comunidad y continuidad. Cada vez que alguien mantiene un proyecto legacy, documenta su historia, o rastrea contribuidores perdidos, está tejiendo los hilos que conectan el pasado computacional con su futuro.
El viaje de Adam entre sus dos mensajes – desde el permiso técnico hasta la reflexión emocional – encapsula por qué la preservación importa: el código sobrevive, pero las historias humanas se pierden si no las capturamos.
EPÍLOGO: Lecciones de la Arqueología de Software
1. Documenta Todo
Esos posts casuales de USENET se convirtieron en evidencia legal crucial décadas después.
2. Licencia Claramente
El comentario de Ed de que «copyleft didnt exist when i wrote it» resalta cómo los panoramas de licencias evolucionan.
3. La Comunidad es Todo
Adam encontró mis artículos porque la comunidad de preservación estaba hablando del proyecto.
4. Las Herramientas Modernas Pueden Revivir Código Antiguo
Melange y CI/CD le dieron al software de 1987 un renacimiento en 2025.
5. La Deuda Técnica es Temporal
Lo que parece tecnología legacy hoy podría ser el tesoro arqueológico de mañana.
6. Preserva las Historias, No Solo el Código
Los «Caleyisms» de Richard son tan valiosos como sus contribuciones técnicas.
LA HISTORIA CONTINÚA
Ambos juegos Conquer están ahora completamente licenciados bajo GPLv3 con empaquetado moderno. No son solo software jugable, sino un caso de estudio completo en:
- Arqueología de software
- Marcos legales para preservación
- Evolución de prácticas de desarrollo a través de cuatro décadas
Los repositorios cuentan la historia en curso:
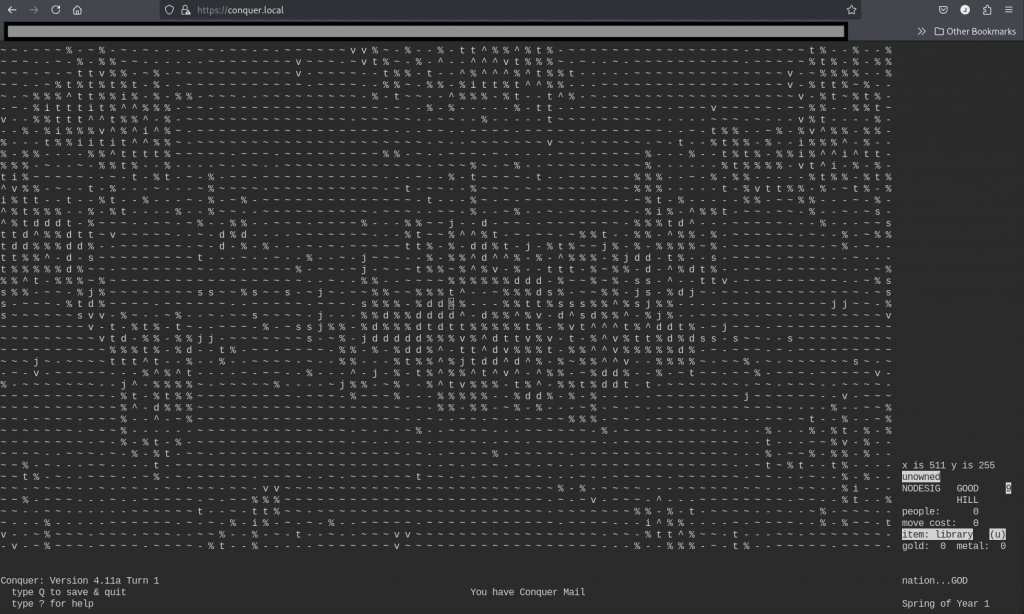
- Conquer v4 – El clásico original

- Conquer v5 – La reescritura avanzada
El próximo capítulo: enseñar estos juegos de estrategia clásicos a una nueva generación de desarrolladores y jugadores, mientras demostramos que los marcos legales apropiados y las herramientas modernas pueden dar una segunda vida a cualquier software histórico.
A veces la mejor manera de aprender tecnología de vanguardia es aplicándola para preservar la historia computacional.
¿Qué software histórico merece preservación en tu campo? ¿Has rastreado alguna vez el linaje del código hasta sus creadores originales?
#SoftwareLibre #CodigoAbierto #PreservacionDeSoftware #Unix #GNU #Linux #Empaquetado #Melange #HistoriaTecnologica #DesarrolloDeJuegos #USENET #GPL #FSF #Debian #ncurses #terminal
Read this article in English / Lee este artículo en inglés:
https://vejeta.com/reviving-classic-unix-games-a-20-year-journey-through-software-archaeology/